Today, rest is a hot topic. Its often ardent followers argue strongly in its favor over RPC-based Web services. Why? What makes REST such a powerful architecture and concept? In this chapter you’ll explore REST as an architecture and begin to learn what makes REST tick. The next chapter dives into even more detail. Given an understanding of these first two chapters, you should be well prepared to work through the concepts and examples throughout the remainder of the book.
What is Representational State Transfer (REST)? Why is every one talking about it now? How do I make use of RESTful services in my own systems? Can the .NET Framework help me produce RESTful services my clients might use? These are excellent questions many people are asking, and they’re some of the topics we’ll cover in this book, starting with this chapter. Since these are probably burning questions, here are some quick answers: REST is a design philosophy that encourages us to use existing protocols and features of the Web to map requests for resources to various representations for manipulation over the Internet. REST isn’t a specific architecture or toolkit, so to use it we need to understand RESTful design philosophy and use the tools we have to create architectures that exhibit RESTful qualities. And the .NET Framework can absolutely help us write RESTful systems!
But often more important than “What are RESTful services?” or “How are they implemented and used?” is “When should we use RESTful techniques?” Where does using them make the most sense? We’ll also examine those questions throughout the book. Sometimes the built-in tools .NET provides are perfectly suited for your architectural needs. Other times REST concepts would be better applied even if you need to write a bit more code at times. The goal is to understand the concepts behind Web data communication so you make an appropriate, informed design decision.
This chapter examines the “what.” Chapter 2, “The HyperText Transfer Protocol and the Universal Resource Identifier,” digs more deeply into the mechanisms that make REST work. The chapters that follow provide working examples of RESTful systems and discuss the architectural merits (or demerits) of each. Our goal is to show you how the various .NET technologies work when used to implement RESTful services and give you the knowledge you need in order to select the right .NET technology for the job. In many cases more than one will work, but some mitigating circumstance or requirement will normally draw your attention to a clear preference.
In any case, let’s begin. Sometimes it’s best to learn a new technology from the bottom up. But in this case, I think it’s a better idea to take a step back and look at a bigger picture. When we dive into the nuts and bolts of REST, having a wider view is helpful when putting the pieces together. Let’s start with a brief discussion of where Web services have been going in recent years, services in general, and how services have historically been built. Knowing that, and taking a look at how the Internet was architected, should lead you to designing architectures that support RESTful services with relative ease.
NOTE
It is not my intention in this chapter to say one technology is “better” than another. Rather, I want to provide an understanding of why REST has become so popular. I also want to show that REST is an architectural style that can be used with great success in many situations. However, as with any tool, you need to understand its strengths and weaknesses. This is exactly why you’ll find the brief discussion of SOAP in the following section. SOAP and its related technologies are also tools. The more you understand, the better armed you’ll be to make the most appropriate architectural choice for your particular application’s needs.
The Shift (Back) to REST
When Tim Berners-Lee and a talented group of engineers and scientists designed the World Wide Web as we know it today, they had several design principles in mind, including the transfer of documents using hypermedia principles (markup, linking to other documents, and so forth), scalability, and statelessness. Their initial idea was to be able to share marked-up documents quickly and simply.
It wasn’t long before people realized that, though sharing documents is good, sharing data outside the context of a Web page is also good. Early in the Internet’s history, circa 1995, the Common Gateway Interface (CGI) was created to handle computational and data-centric requests that didn’t necessarily always fit into the hypertext-based document model. Payment processing, for example. CGI, however, had many issues, not the least of which was the constraints of the early CGI implementations that created a new process to handle each request. Since process creation is expensive in terms of processing and memory, the resulting lack of scalability and higher cost were factors that drove people to look for alternatives.
NOTE
In the spirit of providing interesting examples, CGI is still used for data transfer today. See http://penobscot.loboviz.com/cgidoc/ for a working CGI-based data service.
Another famous approach to handling data-centric Web requests came about in late 1999-the Simple Object Access Protocol, now just known as SOAP. (There were others, such as XML-RPC, but we’ll concentrate on SOAP for this discussion.) SOAP defined a wire protocol that standardized how binary information within the computer’s memory could be serialized to the Extensible Markup Language, or XML. At the time SOAP was invented, XML was also in its infancy (even before XML schemas were standardized). Initially there were no discovery and description mechanisms either, but eventually the Web Service Description Language (WSDL) was settled on. WSDL enabled SOAP-based service designers to more fully describe the XML their service would accept as well as an extensibility mechanism. The SOAP specification didn’t describe the policies that dictate how your service should be used (whether the messages should be encrypted, for example). But using WSDL, this sort of “meta” information could be described, making SOAP-based services more interoperable and widely accepted.
For example, the Web service community came up with a collection of extensional specifications that together are referred to as the WS-* (“WS-star”) specifications. These include WS-Security, WS-ReliableMessaging, WS-Addressing, and WS-Policy, to name just a few. These specifications all essentially added layered metadata to the SOAP payload by modifying the header while keeping the message body intact.
But there is a pattern here we should more closely examine. In the beginning we had simple hypermedia documents. However, as soon as we added the capability to access server-based application data processes, the basic architecture of our applications began moving away from the pure hypermedia model. CGI introduced a “gateway” where none had existed. SOAP introduced a novel use of XML, but this then required servers to accept and handle SOAP requests with arbitrarily complex payloads or negotiate lowest common denominators. Then came WSDL. Before WSDL, you had to precisely match the SOAP-based service’s XML payload format requirements by hand, rather than using automated tools as we do today that consume WSDL, or the service request would fail. With WSDL it became easier to modify the client’s SOAP request to match what the service provider required, but then the server needed to formulate the WSDL, adding more processing requirements and moving the data communication architecture even further away from a pure hypermedia basis. And when the incredible complexity of the WS-* specifications is added, the entire data communication process incorporates processing and metadata transfer completely unforeseen only a few years ago.
There are several good reasons to question the data transfer process as it has evolved, however. To begin, the architecture of the data services migrated away from the original intent of the Internet designers. This in and of itself isn’t so bad. Technologies change and transform all the time, so who’s to say the data service architecture is somehow bad? Actually, it isn’t that it’s “bad.” It’s just that the data services now represent remote procedure calls (RPC), and as such, require additional overhead to formulate the wire protocol-serialization and deserialization of the in-memory binary information to be transmitted back and forth-as well as communicate the serialized information to the single server endpoint.
By simply using this wire protocol and single endpoint, Web services forced a huge architectural change on the Internet (see Figure 1.1). Instead of a server examining the HyperText Transfer Protocol (HTTP) HTTP method-GET, POST, and so forth-and shuttling that request to a resource handler, the server now needs to crack open the HTTP payload and decipher the contents to decide what to do. There is a special HTTP SOAP header that’s designed to assist with method routing, but the point is that the payload will need to be examined and handled much differently than requests for, say, a Web page. Moreover, other Web systems designed to increase scalability and throughput, like caching, are hindered. Since there is one endpoint for the Web service, all possible service invocations can’t be cached, and you lose the performance boost that caching often provides high-throughput systems.
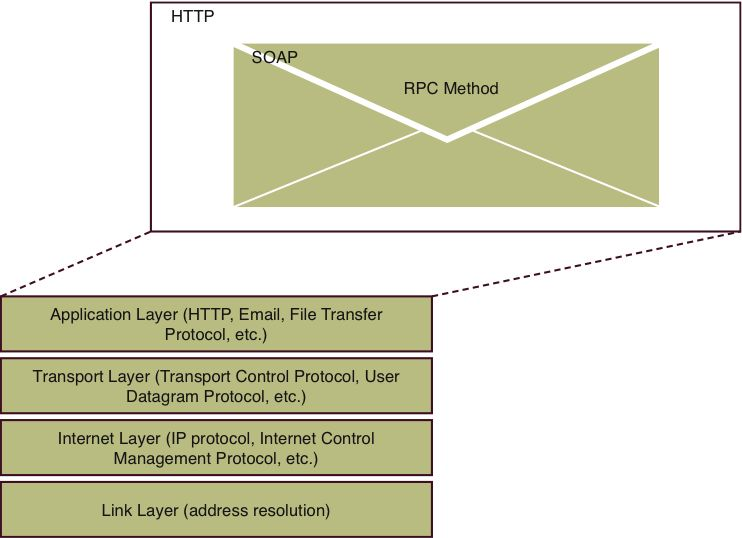
Figure 1.1: The TCP-IP protocol stack hosting SOAP RPC data
The RPC method serialization also adds a tremendous amount of complexity on the client. For example, if you’re writing a .NET Windows application, life is good since the tools Microsoft has provided will accept WSDL and can produce a proxy that rather faithfully mimics the method on the server. The proxy handles all the data serialization and deserialization for you. Your application executes compiled code, has access to nearly unlimited memory from the application’s perspective, and isn’t subject to the same security restrictions as, say, a Web site whose pages are rendered in a Web browser (although perhaps in some cases it should be).
But applications today are moving toward Web-based, hosted scenarios. Take that same data service your Windows application uses and consume it in a Web browser, and things get much more interesting-and not necessarily interesting in a good way. Over time several alternatives have surfaced that manage the proxy task, but they all suffer from some of the same limitations. Security, for example, must necessarily be quite stringent. Security that protects your users from malicious virus software also often interferes with beneficial data services. Another issue commonly faced is the varying ways different browser manufacturers support the basic tool these proxies use, the XmlHttpRequest object. Activating and using the XmlHttpRequest object is different for Firefox than for Internet Explorer, and your client code must be robust enough to take this fact into account. If you also consider the performance penalty usually associated with parsing and working with XML using JavaScript in a browser, you can quickly see why the RPC-style data service is so hard to work with in a generic sense. When the overhead associated with the WS-* specifications is applied, it’s very possible the service couldn’t be used in a browser at all. It depends on how much metadata the service mandates, how many parameters are present in the remote method’s signature, and so forth.
The gist of all of this is that somewhere along the way, all of us associated with designing and developing RPC-based Web services diverted from the basic architecture of the Internet. SOAP and WS-* started from examining various platform-specific solutions like DCOM (Distributed Component Object Model) and CORBA (Common Object Request Broker Architecture), and their ultimate goal was to build those same types of systems in a platform-neutral way. To accomplish this goal, they built on the substrate of some of the emerging Internet protocols of the time. HTTP was chosen as a framing protocol mostly because it was entrenched enough so that people already had port 80 open in the firewall. XML was chosen because the bet was that XML was going to be the platform-neutral meta-schema for data. All the advanced WS-* specifications (Security/Reliability/Transactions) were taking application server features du jour and incorporating those protocols into this platform-neutral protocol substrate.
From an architectural perspective, is all of this necessary? That depends.…
In 2000, which is about the time the SOAP protocol started to take root, Roy Fielding, a co-designer of the HTTP specification, finished his doctoral dissertation, titled “Architectural Styles and the Design of Network-based Software Architectures” (www.ics.uci.edu/~fielding/pubs/dissertation/top.htm). His dissertation revolves around the evaluation of network-based architectures, but his final two chapters introduce the concepts of Representational State Transfer, or REST. His intent was to show how network architectures could be evaluated, the reasons for which he explains here:
Design-by-buzzword is a common occurrence. At least some of this behavior within the software industry is due to a lack of understanding of why a given set of architectural constraints is useful. In other words, the reasoning behind good software architectures is not apparent to designers when those architectures are selected for reuse.
Dr. Fielding didn’t invent the way the Internet works. But he did sit down and rigorously articulate the underlying principles that drive it. In that light, if you peel away the wrapper, REST essentially formalizes data services using concepts inherent in the Internet. Why? Simplicity is one reason, or as Dr. Fielding might argue, why reinvent the wheel when it’s better to understand and use the wheel you already have? Why create complex data service architectures when the Internet as it was originally conceived is perfectly suited for transferring both hypermedia-based documents and data? And to prove his point, as well as earn his doctorate, he describes the principles that guide architectures that should be considered RESTful. More to the point, he mentions that those principles have been in effect since 1994, which is nearly a year before CGI came to the fore.
Put another way, REST describes for us, or perhaps reminds us, that the protocols we use over the Internet are already capable of mapping information and resources. We don’t need to overlay complex protocols-we just need to create architectures that correctly apply existing protocols.
NOTE
If you scan contemporary blogs and articles, you’ll probably find strong proponents of REST arguing against the SOAP RPC model, while strong proponents of SOAP argue that it can nicely manage situations in which REST is not as architecturally appropriate. I personally don’t see the question as being “Is REST right and SOAP wrong?” Rather, I think it is much better to understand both and then evaluate your architectural implementation choices in light of your application’s requirements rather than attempting to blindly adhere to one or the other. Appendix A, “.NET REST Architectural Considerations and Decisions,” has some guidance here.
So what does it mean to be RESTful? Do we need massive specifications and layered metadata? How is data to be communicated without all the trappings of the RPC systems we’ve been building since about the time Dr. Fielding wrote his dissertation? To begin to answer this question, let’s look at some real-world services and pick up some experience along the way. It’s important to understand the contrasting points of view-RPC-based services versus RESTful services-to fully comprehend how a RESTful architecture works, or how it avoids some of the complexities RPC-style architectures rely on.
What Are Web Services?
So let’s go back and formalize things a bit. When we design services, we’re really designing mechanisms to allow external access to our internal application resources. Perhaps we have a computational engine that external clients need to use for financial calculations. Or maybe we have information our clients need to query to support their business processes. We might even have services that invoke actions on behalf of some client activity.
Web services are services that allow machine-to-machine communication using interoperable protocols over a network, and given that definition, both RPC and RESTful services qualify. We’ll look at an example of an RPC-based service first. Let’s say you want your application to include current weather forecast information. This isn’t something you can most likely generate yourself, so you look for a service on the Internet that you can use (ideally for free). As it happens, at least for consumers in the United States, there is a free service available through the National Weather Service described here: www.weather.gov/xml/.
The National Digital Forecast Database (NDFD) is accessible through a SOAP-based Web service. Figure 1.2 shows a small sample Windows Presentation Foundation (WPF) application, which allows you to type in your United States postal code (your Zone Improvement Plan code, or ZIP Code) and receive some basic weather forecast information.
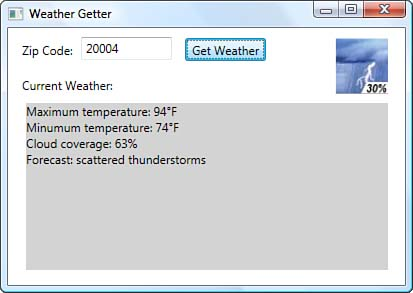
Figure 1.2: Teh Weather Getter National Digital Forecast Database Web service test application
The NDFD service exposes several Web-based methods you can invoke to request forecast information. However, the forecast is indexed by latitude and longitude. Unless you happen to have a Global Positioning Satellite (GPS) receiver with you, chances are good you don’t know your current global position. Luckily, the NDFD service offers several methods for converting more-obtainable location information into global position coordinates. In this case you can provide a ZIP Code and the service will transform that into the appropriate latitude and longitude.
The response to any of the NDFD methods requires deserialization to extract the payload from the SOAP envelope. In this case, each method returns a SOAP response containing another XML document (as a string), and it’s up to you to parse the response XML for the data of interest. As an example, the HTTP response to a ZIP Code conversion request (ZIP Code: 20004, or Washington, D.C.) is shown in Listing 1.1. The latitude and longitude are 38.895 and -77.0373 respectively, as shown toward the end of Listing 1.1.
The response for the actual weather forecast itself is very much more complex and requires quite a bit of processing to present it in a reasonable user interface (and the sample application that calls this service is admittedly weak in that respect). The routines for converting SOAP XML into binary, in-memory objects can be resource intensive, especially if arrays and structures are used. The time it takes and the processor utilization levels can be significant, especially if you’re concerned about high throughput and high scalability (something to keep in mind).
Here’s the point: Traditional Web services are invoked just as you would invoke methods on any locally instanced object you had access to. Because the methods are actually hosted on another server, the methods are known as remote procedure calls, or RPC methods. You as a consumer invoke a method provided by a producer (the remote server) and process the results to suit your needs.
The methods themselves could be thought of as verbs, or perhaps as commands: “Convert my ZIP Code.” “Give me the weather forecast.” Moreover, often the remote methods involve the storage of client state on the server. Processes that invoke methods in a specific order, such as with remote workflow, usually need to keep track of internal state on the server between client method invocations. Windows Workflow Foundation (WF) and Windows Communication Foundation (WCF) since version 3.5 have extensive support for just this purpose. And although the Weather Getter application shown in Figure 1.2 is invoking methods using the HTTP protocol, there is no requirement to do so; this is just how the NDFD implemented their service. You could just as easily invoke methods using the Simple Mail Transfer Protocol (SMTP), Microsoft Message Queue (MSMQ), or even raw network sockets. All that’s necessary is that the SOAP-based packet reaches the destination, assuming you both agree on which transport protocol to use.
There are some issues with this model, however. First, the RPC-based method you’re invoking is embedded in the SOAP protocol, so the server must necessarily be capable of interpreting and reacting to the SOAP request. In production environments, where the SOAP messages can be quite complex, this is a nontrivial task. Second, the basic premise of the HTTP protocol is one of statelessness. Ideally, when the server fields one request and then another from the same client, it has no knowledge of the relationship between the requests. RPC programming methods often encourage the opposite, in which the server must maintain internal state for the duration of the client interaction. Third, although some caching scenarios are possible, in general RPC Web service method invocations return client-specific results and therefore preclude cache support for all possible responses to all possible client requests. RPC requests typically are issued to a single endpoint Uniform Resource Identifier (URI), and knowing this, which method result for which client do you cache? Finally, the methods and their underlying wire protocols can grow in complexity nearly beyond imagination when you apply the WS-* specifications. Not only do you need some serious horsepower on the server to field remote method calls that involve encrypted contents with reliable messaging to be issued to several different intermediaries, but you also need similar capabilities on the client. Something I’ve noted in my various studies is that critics argue that REST requires equivalent processing horsepower for the same levels of confidentiality and verifiability provided by SOAP and its associated specifications. But it also seems that these levels can often be more than many business scenarios necessarily require, kind of like using a sledgehammer to nail a picture to the wall.
Another issue is that it’s hard to change behavior. That is, if you add, remove, or modify your service methods, two things are guaranteed. First, you’ll need to recompile and redeploy your service. And second, your existing service clients will very likely need to revise their code, both their proxies and their internal application processing, and based on the changes you deploy, those changes could be extensive. (Keep this thought in mind…I’ll return to it when I discuss the RESTful example to follow.)
It’s also illuminating to look at a bit of code. When I created the Weather Getter application, I accessed the WSDL document the NDFD service offered to describe the remote methods and data structures I would be required to use. The WSDL document was translated and converted into C# source code using tools provided with the .NET Windows Software Development Kit. When I make NDFD remote method requests in my code, I access the service using the C# proxy the tools created. The proxy hides the complexity of the service invocation, but make no mistake-there is tremendous support in the .NET Framework for servicing RPC-based remote methods, and that software is anything but simple. However, my own software does appear rather simple, as shown in Listing 1.2.
You do not see the code in Listing 1.2 accessing information over the Internet using direct access, such as might be done with .NET’s WebRequest or HttpWebRequest objects. The proxy ndfdXMLPortTypeClient is used instead, and the reason is probably obvious. The SOAP wire protocol must be serialized and deserialized by the proxy for use in the application. “Must” is a strong word, since you could theoretically do the serialization and deserialization yourself, but it makes little sense to do so. The .NET Framework code supporting the proxy is exceptionally complex, well tested, and freely available.
What you also do not see is the management of the service’s endpoint. Using the development tools Microsoft provides, the WSDL conversion not only creates C# code for my application’s use, but also stores the service’s endpoint in the application’s XML-based configuration file. If you open the configuration file, you’ll find only one endpoint mentioned (http://www.weather.gov/forecasts/xml/SOAP_server/ndfdXMLserver.php). That is, even though the NDFD service currently exposes a dozen remote methods, they all are processed by a single service endpoint. This is a direct result of storing the SOAP envelope in the HTTP packet and sending all possible SOAP envelopes to the single service endpoint for processing.
REST-The RPC Web Service Alternative
This discussion of RPC-based Web services was intentionally short. The reason for this is, of course, that this book deals with a different kind of Web service, the RESTful service. Although the RPC style of Web service undoubtedly has a place in our application toolbox, it isn’t a good fit for all usage scenarios we can envision.
To understand what makes a RESTful service tick, it’s important to understand how the Internet (TCP-IP) protocol stack differs as compared to RPC-based Web services (see Figure 1.3). The basic levels are unchanged, but look at the contents of the application layer. This content is no different than it would be for a request issued by your Web browser. (In fact, you’ll use your Web browser to access a RESTful service in a few paragraphs.)
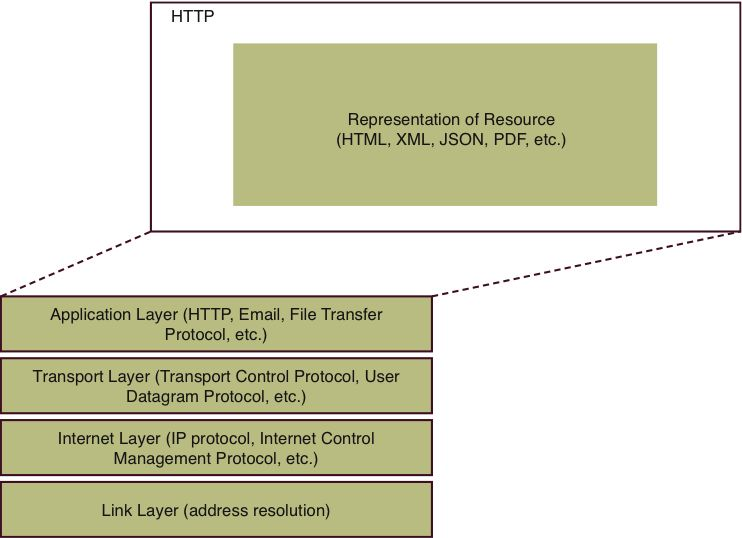
Figure 1.3: The TCP-IP protocol stack hosting RESTful data
Although you’ll look at the HTTP protocol in more depth in Chapter 2, in HTTP protocol terms, items of information you request over the Internet are called resources. Resources are addressable. That is, each resource has an Internet address, identified by its URI.
NOTE
I should make something very clear at this point. REST as an architectural and design concept is not tied to the HTTP protocol. However, in this book we’re talking about implementing RESTful architectures for the Internet using the .NET Framework. Using that more pragmatic outlook, I will discuss REST in terms of HTTP and other Internet specifications. But you should be aware of the distinction and why I seemingly equate REST and HTTP in this and the next chapter.
So let’s consider what this means. First, when we work with .NET-based RESTful services, we’ll be working directly with the HTTP protocol, the design of which is for stateless behavior. And second, since we’ll be accessing those services using the “http:” URI scheme, we’ll be accessing a representation of the resource by the very definition of URI. This is precisely where the “representational” part of REST comes from. Since the entire focus of the Internet is on hypermedia (linking)-after all, we call it “the Web”-representations (or more precisely the application state of your client application) are transferred as links are accessed.
This might not at first sound like a big deal, but the implications are huge. Whether we’re accessing an HTML resource or a RESTful service, we’ll access each in precisely the same way. Want to use a Web browser? REST works. Want to write some JavaScript and make a resource request from a client application? REST works well there too. The mechanisms for doing so already exist, are proven, and are well understood. We don’t need a proxy, and the service endpoint doesn’t need to dig into the HTTP payload to decide which service to invoke. Each RESTful service is identified by a URL. The server returns resource representations to the caller as it always has, whether the client asked for a Web page or for the local area weather forecast.
But this also relates to changing behavior versus updating a resource. In the preceding section I mentioned reasons why changing behavior is difficult, but when clients update a resource in your RESTful service, it isn’t behavior that changes but the resource. Adding new resources is a simple matter-just add a new URI. This doesn’t harm existing clients and doesn’t force inadvertent changes to any client code.
To see REST in action, let’s look at a RESTful service, MusicBrainz. MusicBrainz, or the organization behind the service (www.musicbrainz.org), has compiled a database of musicians, albums, and musical track metadata that you can search. They don’t provide the songs in digital format. Rather, they can tell you which group recorded a particular song, how many songs by the same title have been recorded, how long a particular song track takes to play, and so forth.
RESTful services offer their services directly through URIs, and MusicBrainz is no exception. No SOAP. No service-specific proxies. Just good old direct Internet access. Because of this, your Web browser is as good a consumer of the RESTful service as anything else, at least for demonstration purposes. If you open your browser and type in the following URI, you should see results similar to those shown in Figure 1.4: www.musicbrainz.org/ws/1/artist/?type=xml&;name=puddle+of+mudd.
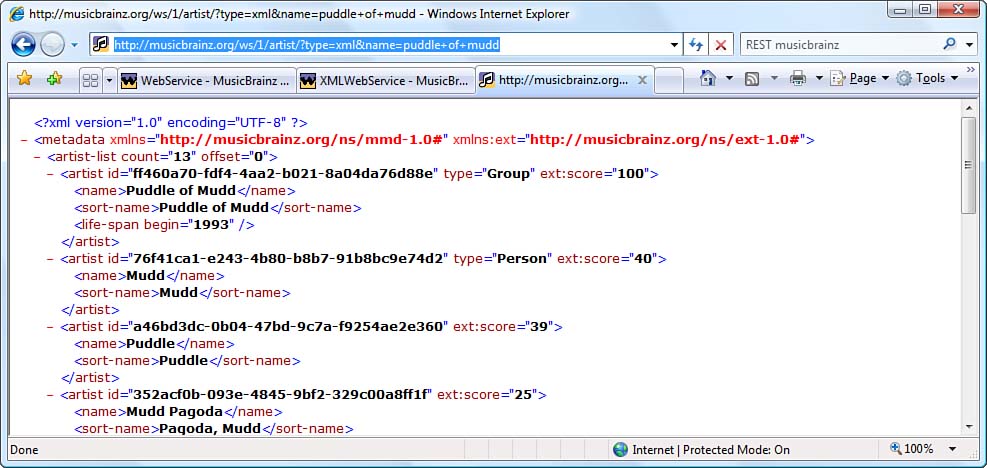
Figure 1.4: Accessing MusicBrainz using a Web browser
By simply looking at the URI, you can tell a lot about the service. Its endpoint is hosted by www.musicbrainz.org. You’ll be performing an artist search. The returned information comes in XML form, which happens to be the only result format MusicBrainz supports at the moment. And you’re searching for information for a group named “Puddle of Mudd.” Each of the services MusicBrainz offers follows this pattern, the details for which are found at the MusicBrainz Web site (http://wiki.musicbrainz.org/WebService). All you need to do is compose a valid URI for the service you’re using and submit that service to the MusicBrainz host. Assuming that all goes well, MusicBrainz will return to you an XML document you can access to extract the search results.
In fact, this is exactly what the Music Searcher sample application does, as shown in Figure 1.5. The document you receive is representative of the data in the MusicBrainz internal data store. Maybe they’re using XML, but it’s more likely they’re using a database. As external users of their system, we don’t (and shouldn’t) have access to their internal implementation. Instead, MusicBrainz provides us with a representation of the requested data. At present, MusicBrainz issues only “plain old XML” (POX), which is XML formatted using their proprietary schema. But other RESTful services are a bit more sophisticated and can export XML in the Atom Syndication Format (ATOM), JavaScript Object Notation (JSON), or even simple HTML. Something else to notice is that you receive a document, which is an object. Objects are nouns. RESTful services deliver representations of data and are considered to be based on nouns rather than on verbs as with RPC-based services. Any changes we would make to the document can be forwarded to the server and its internal resource updated.
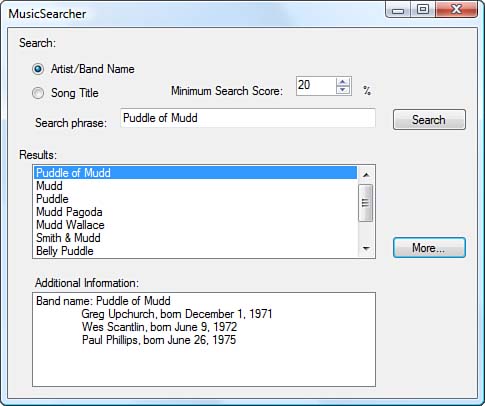
Figure 1.5: The Music Searcher MusicBrainz RESTful service test application
The first service request, which is for a list of artists that match the search criteria provided by the user interface, returns a collection of XML elements. Each element represents a single group along with a “search score,” which is akin to a search result confidence level. The higher the confidence level, the more likely the results represent the group you’re searching for based on the criteria you specified. The Music Searcher lists the groups in descending search score order.
Making the service call is rather simple, as shown in Listing 1.3. The code in Listing 1.3 composes a URI with the search criteria embedded as URI query parameters in typical Internet fashion (i.e., spaces are removed in lieu of plus signs, multiple parameters are separated by an ampersand, and so forth, which is known as URL encoding). The URI is then accessed using .NET’s HttpWebRequest object. The results are returned in XML form, so the code creates an instance of XmlDocument, reads the response stream, and then processes the service’s representation-specific information.
From the code in Listing 1.3, it’s evident that no proxy is being used-the information is requested directly from the server and consumed in the native response format. Moreover, we could send the server an infinite number of URI-formatted requests. Not all of them might be valid, in which case the server would return an error. But the server isn’t tying the services to a single endpoint as with RPC. (The server could do that but probably isn’t…you can’t discern the server implementation based solely on the URI content and formatting.) The server instead can process service requests just as it processes other Web-based requests that are handled by its resource handling architecture.
RESTful Details
If at this point you have an intuitive feeling that RPC-based Web services are different from RESTful ones, your understanding is taking shape. Let’s look at the mechanics of RESTful services in a bit more detail. The goal here is to begin to understand how to evaluate architectures as either RESTful or not and to understand enough to begin to design new architectures to be RESTful.
Generally speaking, RESTful architectures are simpler to implement because you’re using protocols, techniques, and tools you’ve used to develop Web applications from the beginning. HTTP is the protocol RESTful services use, and it defines boundaries your RESTful services will work within. Put another way, HTTP defines the system your architecture will fit into. When you’ve learned how to work with the system, your RESTful architectures fit within the Web ecosystem better than other architectures do. RPC-based services can work over HTTP, but RPC semantics go against the natural flow of the Internet. For example, as mentioned, RESTful architectures inherently dovetail with caching techniques while RPC-based architectures fight it. RESTful architectures marry one resource to one or many URIs, while RPC architectures marry many methods to a single URI.
Four Guiding Principles
If you wanted look at how SOAP-based RPC Web services are composed, you would need to read, comprehend, and implement the requirements set forth in the SOAP specification (www.w3.org/TR/2001/WD-soap12-20010709/). This huge specification describes such things as how individual data types are converted to and from XML, how arrays are stored, and how single messages can be conveyed to multiple recipients with information unique to each recipient contained in the single message.
On the other hand, Dr. Fielding tells us what RESTful systems must abide by to be considered RESTful in his doctoral dissertation. If you were to read his dissertation, you would find that REST, in stark contrast to RPC-based services, is guided by four simple principles:
- Resources maintained by the server are separate from the representations returned to the client.
- Resources on the server are manipulated via the representations issued to the clients.
- The messages used to convey representations to the client are self-describing.
- Application state is transferred using hypermedia techniques.
The sections that follow go into these principles a bit more deeply. But they essentially say that however the server maintains its internal information and processing capabilities, the consumers of the resources are provided only representations of those resources, not the resources themselves. MusicBrainz doesn’t send us their database. Instead, they send us XML representing the returned search information. When a client obtains a representation of a resource, it can modify or delete the resource on the server using the representation it has obtained. If you’re a member, MusicBrainz will allow you to update information in their database, but you do so by returning XML to the server.
Messages issued between client and server do not require complex description standards. Just by looking at a RESTful message, we know the host, the requested resource, the requested representation (the “content type”), and the transport protocol and version being used (HTTP 1.0 or 1.1). And if we want to look for related resources, we should find links to those resources contained in the response we receive when requesting a current resource’s representation. This notion has the unfortunate moniker Hypermedia as the Engine of Application State, or HATEOAS. But it essentially boils down to using hyperlinks to move from URI to URI, allowing you to examine logically related resource representations. The server doesn’t keep track of where your client application is any more than it does my client application. Individual requests for resource representations are unrelated, even with the same client. The only tie you have to other resource representations is through hyperlinks provided to you by the current server response.
Resources
At the heart of REST is the concept of a resource. After all, it’s the representation of the resource that drives us to build RESTful systems. But what is a resource?
We find a somewhat formal definition of resource in the architectural document for the Internet itself (“Architecture of the World Wide Web, Volume One, W3C Recommendation 15 December 2004,” found at www.w3.org/TR/2004/REC-webarch-20041215). There, a resource is defined as such:
The term “resource” is used in a general sense for whatever might be identified by a URI. It is conventional on the hypertext Web to describe Web pages, images, product catalogs, etc. as “resources.” The distinguishing characteristic of these resources is that all of their essential characteristics can be conveyed in a message. We identify this set as “information resources.”
The architectural document further states:
However, our use of the term resource is intentionally more broad. Other things, such as cars and dogs (and, if you’ve printed this document on physical sheets of paper, the artifact that you are holding in your hand), are resources too. They are not information resources, however, because their essence is not information. Although it is possible to describe a great many things about a car or a dog in a sequence of bits, the sum of those things will invariably be an approximation of the essential character of the resource.
What is all of this saying? It says that nearly anything can be a resource. Some resources are more readily handled in electronic form, such as Web pages, product catalogs, and weather forecasts. But you can have other resources that are not electronic, like cars and dogs, and those types of resources will necessarily be approximated when converted to electronic form. In other words, I can’t physically place my car on the Internet, but I can easily place metadata describing my car on the Internet. That metadata forms the electronic resource, the representation for which you would access using a RESTful service. MusicBrainz and its services are a good example. They don’t store the actual artists or albums at their location; instead, they store metadata regarding artists and albums and provide that information to us in XML form. The quality of those resources is directly related to the quality of the metadata, but at least you can make the metadata available, as devotees of eBay can attest to when they try to sell items over the Internet (seewww.ebay.com).
Addressability and the URI
I intentionally sidestepped a bit of the definition of a resource as identified by W3C in the preceding section. Looking again at the Internet’s architectural document, the definition of a resource has this specific statement:
The term “resource” is used in a general sense for whatever might be identified by a URI.
Resources are identified by URIs. And though it might sound like an oversimplification, without a URI you cannot have a resource. That is, if you have something you’d like to place on the Web, unless there is a URI associated with it, it’s not on the Web. I’ll have more to say about this in the next chapter when I get into more detail surrounding URIs.
Types of State
RPC-based Web services are not tied to a specific transport protocol. Given enough time, you could write a SOAP-based service that worked equally well over HTTP and SMTP without changing the encoded SOAP messages themselves. (Note that as of .NET 3.5, you can handle SOAP messages using both Microsoft Exchange Server and Internet Information Services.) SOAP has a definite affinity for HTTP, but HTTP use isn’t required.
REST, on the other hand, is indelibly linked with HTTP when talking about implementing RESTful services using .NET-based technologies. And as you probably know, one of the foundational concepts of the HTTP protocol is that it is a stateless protocol. One HTTP request is completely unrelated to another, and in a pure HTTP world, the server is under no obligation to associate any two or more HTTP requests.
In today’s electronic commerce world, however, we know that Web sites do, in fact, keep track of previous encounters. An obvious example is the Internet shopping cart. If I browse Acme’s Web site and order half a dozen of the famous Eludium Q-36 Explosive Space modulators, I expect to later be able to advance to the “checkout” page, provide my payment information, and complete my purchase transaction. If the checkout page had no idea that I’d wanted to purchase six modulators, there wouldn’t be much point to having a checkout page.
I used that example intentionally, by the way. I slipped in the use of two different kinds of state, one you’re probably familiar with if you’ve ever designed interactive Web sites, and one you might not have thought of as “state.” The first kind of state is session state, and the shopping cart is an example of that kind of stateful behavior. For any given session in which I’m interacting with a Web application, the maintenance of information regarding previous page access represents session state. Another form of session state involves “logging in” to a Web application. We expect to authenticate only once and then access any of the secured resources at will until we log out or are otherwise kicked out (timeout, for example).
The other type of state is application state. The fact that I could maneuver my browser, or any service client for that matter, from the product order page to the checkout page using a button or hyperlink is an example of application state. My “view” into the application is at first a product-centric view and then later a transactional-completion view. Although the two views are obviously related, they’re clearly also different. The Web application I’m working with is presenting me with the parts of the application that apply to the specific tasks I’m trying to accomplish. When I want to select a product, the application presents me with product selection logic. When I later need to pay for the products, the application presents me with the product payment logic.
RESTful systems embrace application state. In fact, application state is so important that I mentioned it as part of the fourth principle of RESTful systems, and we’ll revisit the concept later in the chapter in the section titled “Linking and Connecting.”
RESTful systems eschew session state when it’s hosted on the server, however, and by that I mean any form of server-based session state. (Cookies pose a special problem, which we’ll look at in the “If You Give a Client a Cookie” section later in the chapter.) The concept of a product order page and a checkout page having knowledge of the products to be purchased is a fabrication Web site developers have developed over the years, and admittedly it works. However, strictly speaking, linking the two pages using server-based constructs violates the RESTful architectural style.
This violation has a cost. The session state information must be stored somewhere. It must age and eventually be timed out and destroyed if not explicitly terminated by the client. Although the client initiates and terminates sessions, it’s the server that nearly always bears the responsibility for keeping track of users and their session state. Imagine the mayhem that would ensue if people who purchased goods through Amazon were asked to pay for someone else’s order. The Amazon server must stringently keep track of users and their specific session state.
What’s more, this information often must be made available across a Web farm where multiple servers are active. If you force a piece of equipment to keep track of the specific server a user has been accessing, usually a load balancer, the problem is by far worse. Using server-based session state at all reduces your Web application’s scalability, but this is often a restriction Web site designers are willing to sacrifice to maintain proper application and transactional logic for their particular case. Very, very few experienced Web application designers, however, would force a given user’s session information to remain with a specific server machine for the duration of their session. The effort to do that far exceeds any conceivable value, so alternatives like a “session state server” (a shared database) or a “distributed session cache” are typically used to allow multiple servers to share a single session structure. The cost of maintaining session state is therefore both financial and in terms of performance and system complexity.
This is not to say that maintaining such state is to be avoided at all costs when designing RESTful systems. Far from it. If the client browser generates a URI that moves them between pages while sending those pages session-based information, that’s fine. You probably wouldn’t want to do this with financial information, or even a shopping cart. But other applications we can envision can work perfectly well maintaining session state in this manner. Most Internet search services work in this manner as well.
Therefore, to be considered RESTful, the aspect of session state to avoid involves maintaining the session state on the server. It’s not uncommon for Web site toolkits to implement server-based session state and ask the client to remember a “session key.” Each request made to the server forces this session key to be sent so that the server can tie accesses to resources together.
The reasons for avoiding server-based session state management involve the interplay between client and server. If the server doesn’t maintain session state, the user’s session will never age and require timing out or forced removal. The client controls where it moves within the application, and the server is relieved of maintaining awareness of where in the application the client is currently working. Servers can then more easily cache resource representations, greatly increasing their availability and scalability.
Note
Actually, completely avoiding server-based session state is something RESTful systems do in an ideal world. In the real world, some resource access is limited and accomplished only after successful authentication and authorization, in which “roles” or “permissions” are granted based on authenticated credentials. In those situations in which authentication and authorization are required, REST tends to “look the other way,” although we can imagine solutions that are more RESTful than others if not completely RESTful by nature. The “Security, Authen tication, and Authorization” section has more to say on this matter. Other forms of server-based session state must be avoided at all times.
If You Give a Client a Cookie
If your service gives a client a cookie, it’s entirely likely your service would be considered not RESTful. Dr. Fielding has this to say in Section 6.3.4.2 of his dissertation:
An example of where an inappropriate extension has been made to the protocol to support features that contradict the desired properties of the generic interface is the introduction of site-wide state information in the form of HTTP cookies. Cookie interaction fails to match REST’s model of application state, often resulting in confusion for the typical browser application.
General cookie use is considered not RESTful except in the specific case in which the client controls what cookie to send (by consuming and using the HTTP Set-Cookie header). The more common use for cookies is to maintain some measure of application or session state. In that case, the client no longer has total control over how it progresses through the application. Accessing the same resource through different hyperlinks could easily result in the creation and storage of different cookies. The mere fact that we have different cookies means we have different state. If we have different state when accessing the same resource, the system is not RESTful, as Dr. Fielding explains:
The problem is that a cookie is defined as being attached to any future requests for a given set of resource identifiers, usually encompassing an entire site, rather than being associated with the particular application state (the set of currently rendered representations) on the browser.… [The] next request sent to the same server will contain a cookie that misrepresents the current application context, leading to confusion on both sides.
In general real-world scenarios, this usually isn’t a huge restriction. Web sites as accessed by humans don’t usually suffer greatly when cookies are employed. They often benefit. If you access an Internet search page and it “remembers” your last search because that information was stored in a cookie, the added user interface feature might be considered a good thing. It just depends on your personal preferences. RESTful services, however, are generally designed for electronic access and don’t require such user interface trappings. For them, cookies are simply not used, again as discussed by Dr. Fielding:
Cookies also violate REST because they allow data to be passed without sufficiently identifying its semantics, thus becoming a concern for both security and privacy.
Representations of Resources
Earlier, I mentioned that RESTful services return representations of resources to clients, and that the representations might be HTML, XML, JSON, or whatever other encoding the service is able to produce. How is this accomplished?
The choice of what representations to produce is up to the service designer. MusicBrainz, for example, produces only XML. Other RESTful services are capable of returning information in various representational formats, and there are a couple of ways the client can inform the server which representation it desires. The first technique is known as content negotiation. The second technique is to provide individual URIs for different representational formats.
Content Negotiation
Let’s return to using a RESTful service to ferret out information for Eludium Q-36 Explosive Space modulators. Imagine this URI:
Given only this URI, the service has no idea in what format the client wants the representation. And yet, RESTful services quite often expose URIs that look just like this. So how will the service “know” what representation is desired?
The answer is formally known as content negotiation, but the term makes it sound more complex than it really is. The concept of content negotiation comes from the HTTP Request for Comment (RFC), Section 12, found atwww.w3.org/Protocols/rfc2616/rfc2616.html. When HTTP requests are created, the protocol specifies headers that are used to convey information (as you’ll see in Chapter 2). A few of those headers are most often used to determine what representation to return.
The first header, Accept-Language, tells the server what language you desire, whether it’s English, French, or what have you. If the representation involves language-specific interpretation, this header conveys the desired language to the server. If the header is omitted from the HTTP request, the server is free to issue a default representation, with the server (and the designer) deciding what “default” means.
The other header is the Accept header. The Accept header tells the server specifically what content type to return, whether it’s XML, JSON, XHTML, HTML, ATOM, or whatever. Some typical Accept header values are shown in Table 1.1. If the Accept header is missing or has the value */*, then as with a missing Accept-Language header, the server issues a default representational content type.
If the client provides information to the service, such as a representation to create or modify, the client indicates the content type using the HTTP Content-Type header. The returned content type, whether default or not, will also be identified using the Content-Type header. Something to consider for a RESTful service is that the client might not be, and in all likelihood will not be, a Web browser. In other words, patently returning HTML might not be the best choice for a default representation. You’ll have to decide based on your individual service needs.
URI Design
Content negotiation is completely RESTful because it uses HTTP constructs to issue information. However, the HTTP headers are really just text-based metadata. As such, it isn’t necessarily obvious which representation is to be requested. An alternative is to design your resource URIs with content in mind.
For example, returning to the Eludium Q-36 Explosive Space modulator URI, if we wanted the returned information as English encoded in JSON, the service could expose the URI like so:
The URI clearly tells us that we will be looking at English (the “EN”) as encoded in JSON. This might appear a bit frightening if you take it to the obvious extent. If we support eight languages and five encodings, we have 8 * 5 = 40 different URIs to support. Does this mean our server needs to route 40 different requests?
In reality, no. We would handle this via URL rerouting. In this case, the “Products” resource at www.acme.com would interpret the URI and return to the client the appropriate representation. We’ll look into URL rerouting more in the next chapter when we examine UriTemplate.
Given the two different schools of thought, content negotiation and URI design, which is the more appropriate? This is a matter of opinion. Although it’s a simple task to examine the HTTP headers on the server and route the request to the appropriate handler based on the content of the header, it also masks the client’s desired return content type. It’s a bit more difficult to parse and interpret the URI string in your application logic, but it’s very much apparent which content type is desired just by examining the URI. Dr. Fielding tells us this:
The protocols are specific about the intent of an application action, but the mechanism behind the interface must decide how that intention affects the underlying implementation of the resource mapping to representations. (emphasis added)
He also says this:
Because a client is restricted to the manipulation of representations rather than directly accessing the implementation of a resource, the implementation can be constructed in whatever form is desired by the naming authority without impacting the clients that may use its representations. In addition, if multiple representations of the resource exist at the time it is accessed, a content selection algorithm can be used to dynamically select a representation that best fits the capabilities of that client.
Essentially, Dr. Fielding is leaving it up to you. And so will I.
Linking and Connecting
The final principle of RESTful systems is the concept of maintaining application state through the use of links, otherwise referred to as Hypermedia as the Engine of Application State (HATEOAS). As I’ve mentioned before in this chapter, the Web application you access in your Web browser allows you to traverse both its internal links and any external links that might be present. By navigating any of these links, your “view” into the Web application changes. In other words, the application state, as maintained by the browser, changes. The existence of the links in the HTML documents you’re viewing allows you (and the browser) to move through the application at will. This is what makes the Web the Web. The best part is that this costs your server little to nothing-the additional bytes of the URI as stored on disk and issued via the network. The client makes the choice to navigate and change application state.
RESTful services can exhibit this behavior as well. Representational responses to requests might provide related additional links or linking mechanisms that could be used to traverse the application space. Perhaps the link is represented by another URI as directly embedded in the representation, or a link could be suggested in the HTTP Location header (in some cases). This isn’t to say all representations must return links to other resource representations. However, if other representations exist that are indeed related, you have a mechanism in place to make those resources more readily identifiable.
Security, Authentication, and Authorization
If there is a single area within the REST sphere of influence that is least well defined, it would be how RESTful systems handle authentication and authorization. Things change quickly, so it’s entirely likely that by the time you read this, opinions and options will have changed; but what you see here is how things shape up at the time this was written.
First, let’s get the easy stuff out of the way. If your RESTful service is important enough to require authentication, it’s important enough to merit transport encryption, whether that’s Secure Sockets Layer (SSL), Transport Security Layer (TSL), or even IP Security (IPSec) or a Virtual Private Network (VPN). Authentication issues aside, encrypt your important data using one of these means.
Authorization is also something we can dismiss rather quickly. How your application manages authorization is specific to your application and any framework you use to build your application. Authorization is the process of determining what a validated user can do within your system. Some users might only retrieve resource representations, whereas others have greater system access and can perhaps add or delete resources. ASP.NET, for example, has significant built-in support for authorization, although whether you can use ASP.NET’s implementation without adding your own code is doubtful (see Chapter 6, “Building REST Services Using IIS and ASP.NET,” for more detail). In the end your application merely requires a way to segregate users into those who can perform an activity with your service, or even invoke it at all, and those who cannot. The logic for this isn’t usually very difficult, although admittedly it’s unfortunate that at the present time we must write a lot of it ourselves rather than using reliable frameworks to do the heavy lifting. We can expect this to change over time as frameworks and toolkits grow to embrace RESTful principles.
The toughest nut to crack is authentication. Authentication is the process whereby an anonymous user requests credential validation and is granted access to the application, or in some cases is not granted access. But it’s more than the simple act of logging in-after login, the service must maintain the knowledge that the validated client can now access protected resources. Logging in can be as simple as sending credentials, essentially the username and password, to the server and requesting validation. But what happens then? HTTP is supposed to be stateless. If the request to validate my credentials is forgotten the very next time I make a service request, what good is the system? I will never be allowed to access the service.
Clearly this involves some form of client session state. ASP.NET, if left to its own devices, would create an authentication cookie for you, the default name for which would be .ASPNETAUTH. An ASP.NET HttpHandler, the FormsAuthenticationHandler, then opens and validates the cookie each time the user accesses a secured Web page. And if in the end you decide to force this on your RESTful clients, it wouldn’t be the end of the world. It’s not entirely RESTful, of course, but the cookie contents don’t represent something truly not RESTful like personalization information or a true session key. But even though it’s an option, if possible you should stick to a more fundamental authentication scheme that’s supported directly by HTTP and the Internet in general.
This scheme is of course HTTP Basic Authentication, which is described in RFC 2617 (www.ietf.org/rfc/rfc2617.txt). By itself, HTTP Basic Authentication is considered a very weak form of authentication. But when coupled with secured transport (SSL or TLS), HTTP Basic Authentication’s weaknesses are for all practical purposes mitigated. The power of HTTP Basic Authentication is that it is implemented using the HTTP Authorization header. Since your RESTful service is most likely interpreting HTTP headers anyway, even if using designed URIs for content requests, this represents only one more header to examine. You’ll look more closely at this header in Chapter 2.
Here’s the problem. If your service caches the authentication information in any way, your server is maintaining client session state. The appropriate thing to do is to mandate that the client issue the Authorization header for each and every RESTful service call it makes. This places the added burden on your service to check for and validate every secured service request, but it’s the only true way to be sure that the client is who they claim to be for any given RESTful resource representation request.
Note
When using transport-level security, such as SSL, the HTTP headers are encrypted with the HTTP packet payload. Therefore, the contents of the HTTP Authorization header cannot be discerned by anyone but the client and the server under nominal conditions (i.e., the cipher isn’t compromised).
.NET Tools for Building RESTful Services
If you’re reading this book, your focus will probably be developing RESTful services using Microsoft technologies. Other technologies exist, such as Rails, but it’s more likely you’re familiar with .NET and want to leverage your existing skills and experience. This final section takes a quick look at the basic tools you have to work with.
http.sys and Internet Information Services (IIS)
Although there is a rudimentary development Web server available for use with Microsoft Visual Studio, the production-quality Web server you’ll use is IIS. Early versions of IIS worked entirely in the Windows user mode, which is to say, in traditional application address space. But network drivers work in the kernel, so network information was required to be passed through the kernel/user mode boundary at high rates. This posed a significant performance bottleneck.
To alleviate this bottleneck, as of IIS version 6.0 Microsoft moved much of the IIS functionality into the kernel, the result of which was the creation of http.sys, the kernel-mode HTTP packet processor. In this way, network traffic and raw Web server processing both occur in the kernel, eliminating the kernel/user processor mode switch.
Note
Interestingly, the performance issue wasn’t the driving factor behind the modification to IIS and the release of http.sys. Developer demand to have independent access to port 80 drove the change to IIS. However it happened, it’s a tremendous benefit to Windows Web application developers.
As it happens, what remains of IIS in the user application address space is, in a sense, just another consumer of http.sys. Your own applications can also directly access http.sys and benefit from the architectural benefits that result, not the least of which is that you can directly control Web requests and responses. The performance benefits are significant.
That’s not to suggest that working with IIS results in poor performance. Far from it. Today’s IIS is very performance-minded, and what’s more, ASP.NET constructs are now directly integrated into IIS processing space. You can augment processing by introducing ASP.NET modules directly into the IIS packet processing stream, and offload processing of specific request types to specialized ASP.NET handlers. These techniques can provide a significant increase in performance. We’ll work with both IIS and http.sys in much more detail in Chapter 5, “IIS and ASP.NET Internals and Instrumentation.”
HttpListener
When working with http.sys, you’re working directly with Windows internal components. .NET provides a wrapper class for http.sys called HttpListener. By using HttpListener, you can create managed code that accepts HTTP packets directly from the network protocol stack, and you can work with those packets in a synchronous or asynchronous manner. HttpListener employs the familiar .NET eventing model to make your application aware of incoming packets, and you have total control over the packet processing and response creation and disposition. In effect, your application becomes a Web server itself. We’ll work with HttpListener in Chapter 2.
ASP.NET
Without a doubt, ASP.NET offers a huge boost to producing RESTful services. It’s packed with tools you can use, and what’s more, if you’re an experienced ASP.NET developer, writing RESTful services using ASP.NET will be easy and familiar to you.
ASP.NET now comes in two different varieties, or, more precisely, provides two different user interface models. The first is the traditional ASP.NET page mode in which HTTP responses are generated based on Web Forms. Web Forms model Web user interaction using programming techniques similar to traditional Windows applications-clicking buttons on the client results in events on the server you can handle, for example. You also have full access to the current request’s context object, and through that you can decipher incoming HTTP headers and create an appropriate response.
The second user interface model is the model-view-controller, or MVC. Although the traditional ASP.NET page model is useful and allows for rapid Web development, it tends to couple the user interface components with logic that drives them. This makes integrated testing more difficult and mars the distinction between business logic and user interface. The ASP.NET MVC framework was developed to alleviate this problem. With MVC, there is a clear distinction between how the data to be presented is stored (the model), processed (the controller), and displayed (the view). Test-driven development is now possible, and there is a clear “separation of concerns” (the MVC mantra). Moreover, the MVC framework relies on a powerful URL mapping component that greatly assists you when designing URIs for your system. No more reason to design your systems to support ugly URLs!
We’ll look deeply into ASP.NET’s traditional page handling model in Chapter 6 and its new MVC model in Chapter 7, “Building REST Services using ASP.NET MVC Framework.” The .NET tools that support MVC’s URL mapping are things we’ll cover in detail in Chapter 2.
Windows Communication Foundation
No discussion of REST and .NET would be complete without looking at the Windows Communication Foundation (WCF). WCF was created to unify the programming models for a variety of very different communication mechanisms, such as .NET Remoting, Web technologies, and message queuing. Because of this, it’s an ideal candidate for creating RESTful services, and indeed you’ll find such support in WCF today. Chapter 8, “Building REST Services using WCF,” gets you working with WCF in general and introduces you to the ADO.NET Data Services framework, which is built atop WCF. You’ll then take your WCF-based RESTful services into the cloud using Microsoft’s Azure platform in Chapter 9, “Building REST Services Using Azure and .NET Services.”
Where Are We?
In this chapter we looked at both RPC and RESTful services-their strengths as well as possible architectural detractions. RPC services map many methods to one URI, and because of this by their very nature they’re different architecturally than traditional Web systems. The server must dig into the payload to process the methods, and because of that, things like caching and discovery are not typically possible. REST, on the other hand, maps resources to URIs. Each resource has at least one URI but can have several URIs. REST URIs are discoverable, and REST requests themselves are self-describing.
REST is based on the notion that requests for resources are provided representations of those resources, and if the underlying resources should require modification, the resource is manipulated via the representation. RESTful service consumers can navigate through the service application space using URIs just as human users would do using hyperlinks to navigate to different Web pages.
Both RPC and REST have their place in today’s Web application. RPC services, though complex, offer architectural options that REST services do not, such as message-based encryption and digital signatures, multiple intermediate recipients, and federation. REST offers simplification and a return to fundamental Internet concepts when providing for data communication and service processing.
The next chapter takes you deep into the HTTP protocol, which is the engine that drives REST. There you’ll see how the protocol works and what you need to understand to properly handle RESTful service requests. You’ll also look at .NET support for processing and interpreting URIs, because the URI is central to RESTful architectures and concepts.
No comments:
Post a Comment